
Replication is one of the core issues in system architecture.
Cluster Topology#
Suppose we use a standard 4-unit configuration: primary, synchronous replica, delayed backup, and remote replica, identified by letters M, S, O, R respectively.
- M: Master, Main, Primary, Leader - the primary database, authoritative data source.
- S: Slave, Secondary, Standby, Sync Replica - synchronous replica that must be directly attached to the primary
- R: Remote Replica, Report instance - remote replica that can be attached to primary or synchronous replica
- O: Offline - offline delayed backup that can be attached to primary, synchronous replica, or remote replica.
Depending on the attachment targets of R and O, replication topology relationships have the following options:

Among these, topology 2 has significant advantages:
When using synchronous commit, for safety reasons, there must be more than one synchronous replica, so that when using ANY 1 or FIRST 1 synchronous commit, the primary won’t hang due to replica failures. Therefore, offline database O should be directly attached to the primary: in implementation details, delayed backup can be implemented using log shipping, which can decouple online databases from delayed databases. Log archiving uses the built-in pg_receivewal in synchronous mode (i.e., pg_receivewal acts as a “replica” rather than the offline database instance itself).
On the other hand, when using synchronous commit, if M fails and failover to S occurs, S also needs a synchronous replica to avoid hanging immediately after switching due to synchronous commit. Therefore, remote replicas are suitable for attaching to S.


Failure Recovery#
When failures occur, we need to restore the production system as quickly as possible, for example through failover, and restore the original topology structure when time permits afterwards.
- P0: (M) Primary failure should be restored within seconds to minutes
- P1: (S) Replica failure affects read-only queries, but primary can handle it temporarily, tolerating minutes to hours
- P2: (O, R) Offline and remote replica failures may have no direct impact, failure tolerance can be relaxed to hours to days
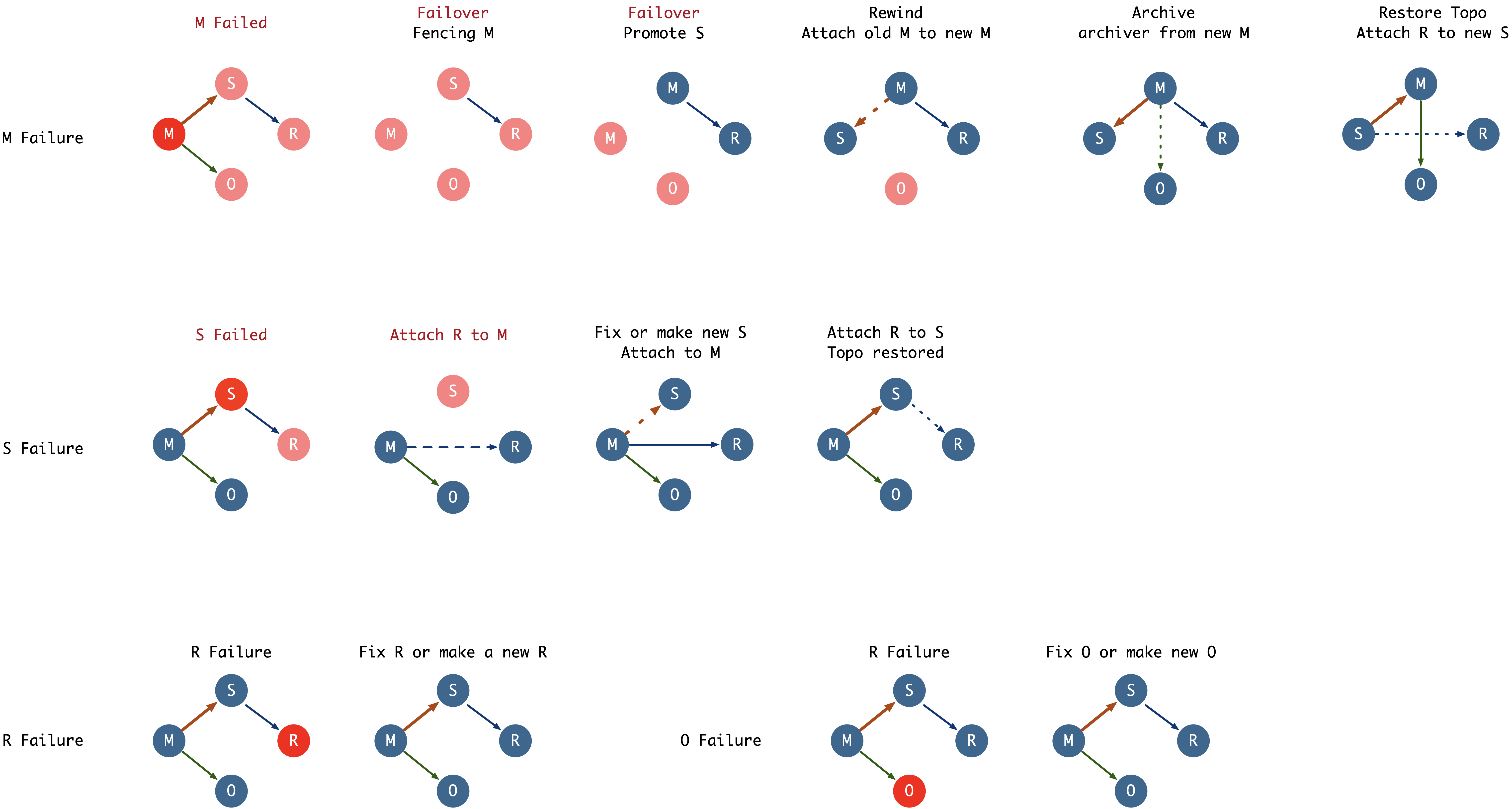
When M fails, it affects all components. Failover must be executed to promote S to the new M to restore the system as quickly as possible. Manual failover includes two steps: Fencing M (from heavy to light: shutdown, stop database, change HBA, close connection pool, pause connection pool) and Promote S. Both operations can be completed in a very short time through scripts. After failover, the system is basically restored. The original topology structure needs to be restored afterwards. For example, convert the original M to a new replica through pg_rewind, attach O to the new M, attach R to the new S; or after repairing M, return to the original topology through planned failover.
When S fails, it directly affects R. As a hotfix, we can change R’s replication source from S to M to fix R’s impact. Meanwhile, redistribute S’s original traffic to other replicas or M through connection pool redirection, then we can slowly investigate and fix issues on S.
When O and R fail, since they have neither significant direct impact nor direct descendants, simply recreating them is sufficient.
Implementation#
PostgreSQL Testing Environment provides a sample 3-node cluster containing M, S, O nodes. R node is a type of S, so it’s omitted here.
Here, the primary directly attaches two “replicas”: one is the S node, and the other is the WAL log archiver on the O node. In cases with very low data loss tolerance, both can be configured as synchronous replicas.





