MongoDB was once an amazing technology that allowed developers to break free from relational database “schema constraints” and quickly build applications. However, over time, MongoDB abandoned its open-source nature, making it unavailable for many open-source projects and early commercial ventures.
Most MongoDB users don’t actually need the advanced features MongoDB provides, but they do need an easy-to-use open-source document database solution. PostgreSQL’s JSON functionality support is already comprehensive: binary storage JSONB, GIN arbitrary field indexing, various JSON processing functions, JSON PATH and JSON Schema. PostgreSQL has long been a fully-featured, high-performance document database. But providing alternative functionality is different from direct emulation.
To fill this gap, FerretDB was born, aiming to provide a truly open-source MongoDB alternative. This is a very interesting project, previously named “MangoDB” but changed to its current name FerretDB in version 1.0 due to suspicions of trademark conflict with “MongoDB” (Mango DB vs Mongo DB). FerretDB can provide a smooth migration path for applications using MongoDB drivers to transition to PostgreSQL.
Its function is to make PostgreSQL masquerade as MongoDB. It’s a protocol conversion middleware/proxy that provides MongoDB Wire Protocol support for PostgreSQL. The last plugin to do something similar was AWS’s Babelfish, which made PostgreSQL compatible with SQL Server’s wire protocol to masquerade as Microsoft SQL Server.
FerretDB, as an optional component, greatly benefits the enrichment of the PostgreSQL ecosystem. Pigsty provided Docker-based FerretDB templates in version 1.x and native deployment support in v2.3. Currently, the Pigsty community has become a partner with the FerretDB community, and we will conduct in-depth cooperation and adaptation support in the future.
This article briefly introduces FerretDB’s installation, deployment, and usage.
Configuration#
Before deploying a Mongo (FerretDB) cluster, you need to define it using relevant parameters in the configuration inventory. The following example uses the meta database of the default single-node pg-meta cluster as the underlying storage for FerretDB:
ferret:
hosts: { 10.10.10.10: { mongo_seq: 1 } }
vars:
mongo_cluster: ferret
mongo_pgurl: 'postgres://dbuser_meta:DBUser.Meta@10.10.10.10:5432/meta'Here, mongo_cluster and mongo_seq are essential identity parameters. For FerretDB, there’s also a mandatory parameter mongo_pgurl, which specifies the location of the underlying PostgreSQL.
You can use services to access highly available PostgreSQL clusters and deploy multiple FerretDB instance replicas with L2 VIP binding to achieve high availability at the FerretDB layer itself.
ferret-ha:
hosts:
10.10.10.45: { mongo_seq: 1 }
10.10.10.46: { mongo_seq: 2 }
10.10.10.47: { mongo_seq: 3 }
vars:
mongo_cluster: ferret
mongo_pgurl: 'postgres://test:test@10.10.10.3:5436/test'
vip_enabled: true
vip_vrid: 128
vip_address: 10.10.10.99
vip_interface: eth1Management#
Creating Mongo Clusters#
After defining the MONGO cluster in the configuration inventory, you can use the following command to complete the installation.
./mongo.yml -l ferret # Install "MongoDB/FerretDB" on the ferret groupSince FerretDB uses PostgreSQL as underlying storage, repeatedly running this playbook is usually harmless.
Removing Mongo Clusters#
To remove a Mongo/FerretDB cluster, run the mongo.yml playbook’s subtask: mongo_purge, using the mongo_purge command line parameter:
./mongo.yml -e mongo_purge=true -t mongo_purgeInstalling MongoSH#
You can use MongoSH as a client tool to access FerretDB clusters
cat > /etc/yum.repos.d/mongo.repo <<EOF
[mongodb-org-6.0]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/6.0/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-6.0.asc
EOF
yum install -y mongodb-mongoshOf course, you can also directly install the mongosh RPM package:
rpm -ivh https://mirrors.tuna.tsinghua.edu.cn/mongodb/yum/el7/RPMS/mongodb-mongosh-1.9.1.x86_64.rpmConnecting to FerretDB#
You can use MongoDB connection strings and MongoDB drivers in any language to access FerretDB. Here’s an example using the mongosh command-line tool installed above:
mongosh 'mongodb://dbuser_meta:DBUser.Meta@10.10.10.10:27017?authMechanism=PLAIN'
mongosh 'mongodb://test:test@10.10.10.11:27017/test?authMechanism=PLAIN'PostgreSQL clusters managed by Pigsty default to using scram-sha-256 as the default authentication method. Therefore, you must use PLAIN authentication to connect to FerretDB. Refer to FerretDB: Authentication for detailed information.
You can also use other PostgreSQL users to access FerretDB by specifying them in the connection string:
mongosh 'mongodb://dbuser_dba:DBUser.DBA@10.10.10.10:27017?authMechanism=PLAIN'Quick Start#
You can connect to FerretDB and pretend it’s a MongoDB cluster.
$ mongosh 'mongodb://dbuser_meta:DBUser.Meta@10.10.10.10:27017?authMechanism=PLAIN'MongoDB commands are translated to SQL commands and executed in the underlying PostgreSQL:
use test # CREATE SCHEMA test;
db.dropDatabase() # DROP SCHEMA test;
db.createCollection('posts') # CREATE TABLE posts(_data JSONB,...)
db.posts.insert({ # INSERT INTO posts VALUES(...);
title: 'Post One',body: 'Body of post one',category: 'News',tags: ['news', 'events'],
user: {name: 'John Doe',status: 'author'},date: Date()}
)
db.posts.find().limit(2).pretty() # SELECT * FROM posts LIMIT 2;
db.posts.createIndex({ title: 1 }) # CREATE INDEX ON posts(_data->>'title');If you’re not very familiar with MongoDB, here’s a quick start tutorial that also applies to FerretDB: Perform CRUD Operations with MongoDB Shell.
If you want to generate some sample load, you can use mongosh to execute the following simple test script:
cat > benchmark.js <<'EOF'
const coll = "testColl";
const numDocs = 10000;
for (let i = 0; i < numDocs; i++) { // insert
db.getCollection(coll).insert({ num: i, name: "MongoDB Benchmark Test" });
}
for (let i = 0; i < numDocs; i++) { // select
db.getCollection(coll).find({ num: i });
}
for (let i = 0; i < numDocs; i++) { // update
db.getCollection(coll).update({ num: i }, { $set: { name: "Updated" } });
}
for (let i = 0; i < numDocs; i++) { // delete
db.getCollection(coll).deleteOne({ num: i });
}
EOF
mongosh 'mongodb://dbuser_meta:DBUser.Meta@10.10.10.10:27017?authMechanism=PLAIN' benchmark.jsYou can check FerretDB’s supported MongoDB commands, along with some known differences, which usually aren’t major issues for basic usage.
- FerretDB uses the same protocol error names and codes, but the exact error messages may be different in some cases.
- FerretDB does not support NUL (
\0) characters in strings. - FerretDB does not support nested arrays.
- FerretDB converts
-0(negative zero) to0(positive zero). - Document restrictions:
- document keys must not contain
.sign; - document keys must not start with
$sign; - document fields of double type must not contain
Infinity,-Infinity, orNaNvalues.
- document keys must not contain
- When insert command is called, insert documents must not have duplicate keys.
- Update command restrictions:
- update operations producing
Infinity,-Infinity, orNaNare not supported.
- update operations producing
- Database and collection names restrictions:
- name cannot start with the reserved prefix
_ferretdb_; - database name must not include non-latin letters;
- collection name must be valid UTF-8 characters;
- name cannot start with the reserved prefix
- FerretDB offers the same validation rules for the
scaleparameter in both thecollStatsanddbStatscommands. If an invalidscalevalue is provided in thedbStatscommand, the same error codes will be triggered as with thecollStatscommand.
Playbooks#
Pigsty provides a built-in playbook: mongo.yml, for installing FerretDB clusters on nodes.
mongo.yml#
This playbook consists of the following subtasks:
mongo_check: Check mongo identity parametersmongo_dbsu: Create mongod operating system usermongo_install: Install mongo/ferretdb RPM packagesmongo_purge: Clean existing mongo/ferretdb clusters (not executed by default)mongo_config: Configure mongo/ferretdbmongo_cert: Issue mongo/ferretdb SSL certificatesmongo_launch: Start mongo/ferretdb servicesmongo_register: Register mongo/ferretdb with Prometheus monitoring
Monitoring#
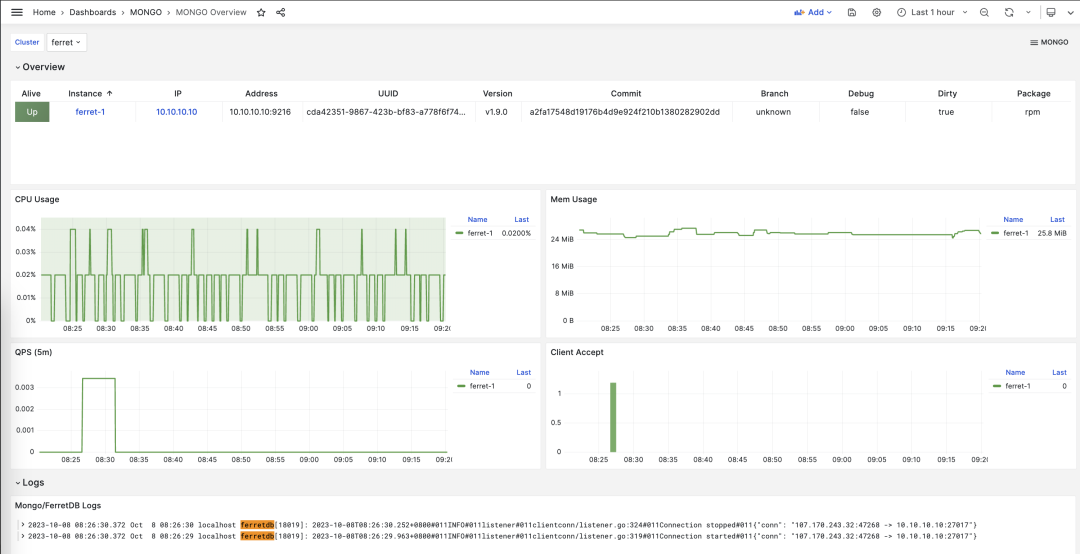
The MONGO module provides a simple monitoring dashboard: Mongo Overview
Mongo Overview#
Mongo Overview: Mongo/FerretDB cluster overview
This monitoring dashboard provides basic monitoring metrics for FerretDB. Since FerretDB uses PostgreSQL as the underlying storage, for more monitoring metrics, please refer to PostgreSQL’s own monitoring.
Parameters#
The MONGO module provides 9 related configuration parameters, as shown in the following table:
| Parameter | Type | Level | Comment |
|---|---|---|---|
mongo_seq | int | I | mongo instance number, required identity parameter |
mongo_cluster | string | C | mongo cluster name, required identity parameter |
mongo_pgurl | pgurl | C/I | PGURL connection string used by mongo/ferretdb, required |
mongo_ssl_enabled | bool | C | Whether mongo/ferretdb enables SSL? Default false |
mongo_listen | ip | C | mongo listen address, default empty listens on all addresses |
mongo_port | port | C | mongo service port, default uses 27017 |
mongo_ssl_port | port | C | mongo TLS listen port, default uses 27018 |
mongo_exporter_port | port | C | mongo exporter port, default uses 9216 |
mongo_extra_vars | string | C | MONGO server extra environment variables, default empty string |