

The day before yesterday at the HOW 2025 conference roundtable, Chairman Xiao asked some interesting questions about AI, databases, and DBAs. Here are Feng’s views, organized and published.
OLTP / OLAP: Who Gets Revolutionized First?#
Question: In OLTP/OLAP domains, which field is AI more likely to bring “revolutionary” changes to first, and how should DBAs, data analysts, and architects respond to these changes?
Feng: “Revolutionary” essentially means directly eliminating job positions. For the OLTP domain, this means AI eliminating DBAs; for the OLAP domain, this means eliminating the work of data analysts and data developers. The current trend is clear - job positions in the OLAP domain are being replaced, with numerous NL2SQL solutions emerging.
Meanwhile, Claude Code is replacing junior to mid-level programmers at an astonishing rate. Data analysts and data developers who write SQL, as a coding profession, also fall within this replacement spectrum. We can see various “intelligent analysis” solutions, spreadsheets, database MCPs, Text2SQL/NL2SQL solutions popping up everywhere.

However, unlike the abundant programming data samples on GitHub, the public data accumulation of operations/database management experience is very scarce. SREs and DBAs face difficulties in direct replacement in the short term due to lack of training data and long feedback validation loops. Therefore, there’s no doubt that AI’s “revolutionary” changes will first occur in the OLAP domain.
A vivid example is OpenAI founding member (author of “Software 3.0 Era, Paradigm Shift Brought by AI”), father of Vibe Coding, Andrej Karpathy, who mentioned in his keynote speech at YC AI Startup School that he spent one day cobbling together a menu illustration app, but it took him a whole week to deploy this app online - OPS became the bottleneck of Vibe Coding.

Nevertheless, Agent replacing DBAs is only a matter of time. Maybe three years, maybe five years, eventually DBA work in the OLTP domain will be conquered by AI within a few years. Cloud computing and local management software will automate 70%-90% of the work, while AI Agents will handle the remaining 9%, possibly leaving less than 1% or even one-thousandth of difficult problems for top-tier DBAs to handle.
Integration vs Specialization: How to Choose?#
Question: Will the database field move toward “integration” or “specialization”, and how should enterprises make reasonable choices based on their needs?
Feng: Many fields have a “pendulum” that swings back and forth based on the balance of forces. Currently, hardware performance is advancing rapidly, and database (PostgreSQL) extensions are becoming increasingly rich. The pendulum in the database field is clearly swinging toward “integration”, leaving smaller and smaller ecological niches for specialized components.
A few days ago, a friend asked me about a vector RAG scenario - should they use PostgreSQL + pgvector or Milvus? I asked how much data they had - 20 million records. I replied that at this scale, don’t bother with complications. Over 100GB of data in PG is trivial - I’ve seen PG vector tables of over ten TB running perfectly fine. If your data volume increased by several hundred times, having Taobao’s image search scenario with hundreds of billions or trillions of scale, using a dedicated vector database makes sense, but you’re already using PG, and at this scale, why create trouble for yourself?
Similarly, I’ve seen several ridiculous stories where businesses claimed super high growth and immediately applied for a horizontally sharded database setup, only to end up with just a few dozen GB of data. If your data doesn’t even reach dozens of TB, you don’t need any distributed NewSQL database - OpenAI can support 500 million monthly active users with one primary and forty read replicas of PG, so 99.99% of businesses can solve all problems with one PostgreSQL. Distributed databases are a false need, and this is even starting to apply to OLAP analytics/big data.

We can compare PostgreSQL to smartphones - they can make calls, GPS navigation, take photos, and do all sorts of things. There are indeed specialized scenarios - like maritime navigation needing satellite phones, commercial photography possibly needing professional DSLR cameras, but these niche markets are several orders of magnitude smaller than the smartphone market, and most users only need one phone to solve all their problems.

I believe that currently, object storage, APM, and OLAP are a few fields still worthy of having dedicated database products. Other database subdivision niches have basically converged to the above state. Moreover, the threshold for using specialized components is getting higher and higher, increasingly distant from most application scales. We can expect that at some point in the future, the database world will achieve unity and convergence (Database Mars Collides with Earth: When PG Falls in Love with DuckDB / Timescale / Promescale).

Premature optimization is the root of all evil - paying the cost in complexity, expense, manpower, and consistency maintenance for attributes you don’t need is meaningless. When enterprises are choosing databases, they must keep their eyes open and not busy themselves with things they don’t need - and PostgreSQL is undoubtedly the default safe choice in the database field.
AI Era DBAs: Where to Go?#
Question: From DBA to DBAA, how should DBAs adapt to changes and impacts in the AI era?
I recently rebuilt Pigsty’s official website using Claude Code and Cursor, with excellent results. You can think of Claude Code as a senior engineer with a monthly salary of $100 (actually you can buy several with a $20 package!), working diligently 24 hours a day for you. What does this mean? This means a solo architect now has an entire team of standby senior programmers.
AI is extremely beneficial to experts. AI in the hands of experts can deliver 10x the performance of ordinary engineers - the logic behind this is that experts can immediately propose correct questions, precise context, and intuitive judgment, and have the ability to verify Code Agent solutions. Ordinary developers often lack answer verification capabilities and sound intuition for asking the right questions. Architects can command a bunch of Code Agents to replace junior engineers in producing output.
This also means that the IT field is very likely to experience class solidification and division - junior engineers’ upward path is blocked by Code Agents, fixed as Code Agents’ mouthpieces and human glue. Moreover, because there aren’t as many scenarios and failures for new people to practice and grow from, there may only be that many senior DBAs and architects in the future.
For experts at the pyramid’s peak, this is a major positive development. This means experts’ capabilities can be rapidly replicated through two methods: through Coding Agents, settling experts’ experience faster into replicable management software, eliminating 90% of database chores; then on this foundation, through DBA Agents, settling experts’ experience into Prompts/knowledge bases, solving 9% of routine problems, leaving the remaining 1% (maybe 0.1%) of work for experts to handle manually.
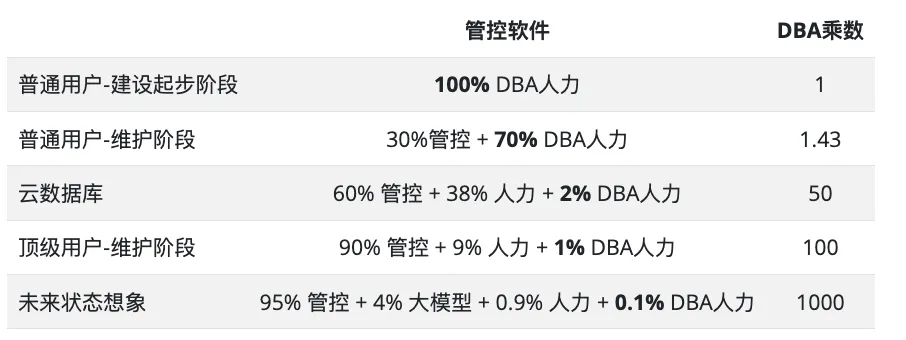
This means a DBA database expert can achieve hundreds to thousands of times leverage through management and Agents. For example, many customers’ questions I consult on, I throw to GPT o3-pro to solve. I only need to ask the right questions and verify answer validity, completing work that would originally take ten times more time. This is the operating mode of super individuals and one-person companies, allowing me to serve over ten clients while maintaining time freedom. I call this new model Service as Software (SaaS).
This is actually the working model of cloud vendor cloud database RDS teams. Top PG DBA experts like Brother De can serve thousands of customers through cloud management software, first through fourth-tier customer service and Agents. Of course, he might have had to rely on cloud platform capabilities before, but now with open-source PG management platform Pigsty, he can completely come out as a PG consultant, deliver with Pigsty, assist with Agents, and handle questioning and troubleshooting himself, similarly becoming a database super individual.

For ordinary DBAs, I think there are many opportunities here too. A significant trend is that database expertise has become the most irreplaceable part of Vibe Coding. Why do I say this? Let’s look at how current AI/SaaS entrepreneurs deliver and produce output.
Best practice is usually to cobble together a frontend with Next.js hosted on Vercel or Cloudflare, with a “BaaS” database like Supabase behind it - the backend is completely eliminated, and frontend Vibe Coding is relatively easy, but mastery and understanding of Postgres underneath Supabase is a relatively scarce skill. Building and maintaining production-grade PostgreSQL/Supabase clusters has basically become the bottleneck chokepoint in the entire stack.
This is a huge positive for DBAs - because Claude Code has brought everyone’s programming abilities to the same level, what matters now is general integration capabilities and scarce database/DBA experience. The PG DBA community already possesses the latter, giving them an inherent advantage over other engineers at the same level.
PG DBAs should fully leverage this current advantage, arm themselves with Code Agents (and open-source PostgreSQL database management Pigsty), transforming themselves into new-generation full-stack architects + managers, striking first to occupy ecological high ground while others are still struggling with database hard bones.
Advertisement Time#
As usual, no article without ads! 😁
Open-source free enterprise-grade PostgreSQL distribution: Trust Pigsty
https://pgsty.com, this is one of only two open-source PostgreSQL solutions on the market that can self-build Supabase. It lets you install enterprise-grade PostgreSQL/Supabase/MinIO/Redis/… database services with high availability, backup recovery, monitoring systems, IaC, connection pooling, and access control on virtual machines/physical machines/cloud/ servers with one click, and solves Nginx, domain names, HTTPS, Docker, images, software source bypassing and other issues in one go…





