

A year after the last major incident, Alibaba-Cloud suffered another massive outage, creating an unprecedented record in the cloud computing industry — simultaneous failures across all global regions and all services. Since Alibaba-Cloud refuses to publish a post-mortem report, I’ll do it for them — how should we view this epic failure case, and what lessons can we learn from it?

What happened?#
On November 12, 2023, the day after Double 11, Alibaba-Cloud experienced an epic meltdown. All global regions simultaneously experienced failures, setting an unprecedented industry record.
According to Alibaba-Cloud’s official status page, all global regions/availability zones ✖️ all services showed anomalies, spanning from 17:44 to 21:11, lasting three and a half hours.
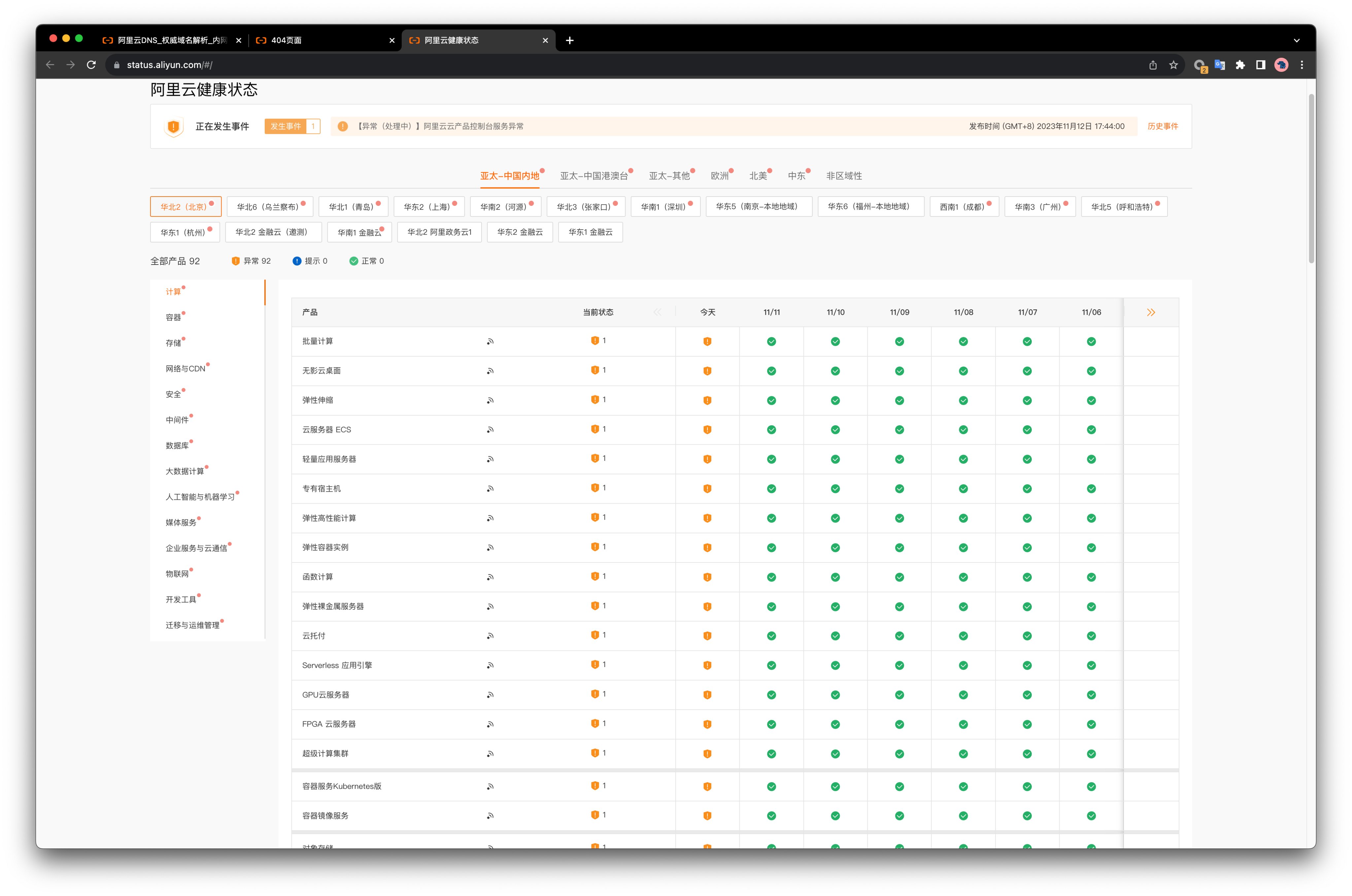
Alibaba-Cloud Status Page
Alibaba-Cloud’s announcement stated:
“Cloud product consoles, management APIs and other functions were affected, OSS, OTS, SLS, MNS and other products’ services were affected, while most products like ECS, RDS, networking etc. were not affected in their actual operations”.
Numerous applications relying on Alibaba-Cloud services, including Alibaba’s own suite of apps: Taobao, DingTalk, Xianyu, … all experienced issues. This created significant external impact, with “app crashes” trending on social media.
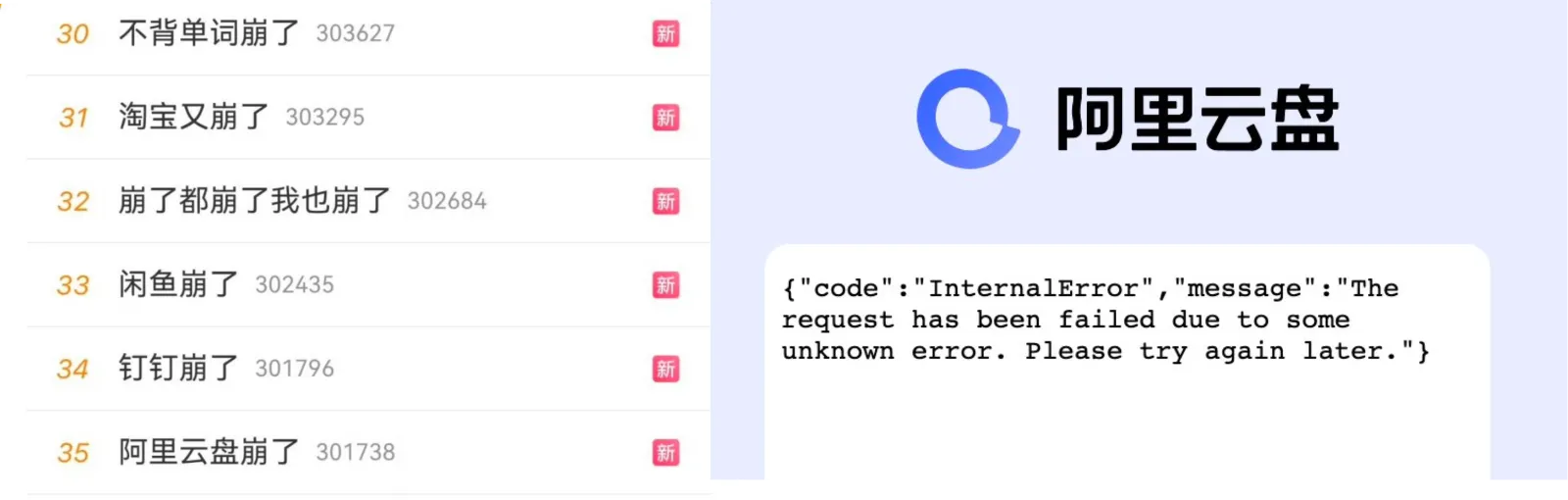
Taobao couldn’t load chat images, courier services couldn’t upload proof of delivery, charging stations were unusable, games couldn’t send verification codes, food delivery orders couldn’t be placed, delivery drivers couldn’t access systems, parking gates wouldn’t lift, supermarkets couldn’t process payments. Even some schools’ smart laundry machines and water dispensers stopped working. Countless developers and operations staff were called in to troubleshoot during their weekend rest…
Even financial and government cloud regions weren’t spared. Alibaba-Cloud should feel fortunate: the outage didn’t occur on Double 11 itself, nor during government or financial sector working hours, otherwise we might have seen a post-mortem analysis on national television.
What was the cause?#
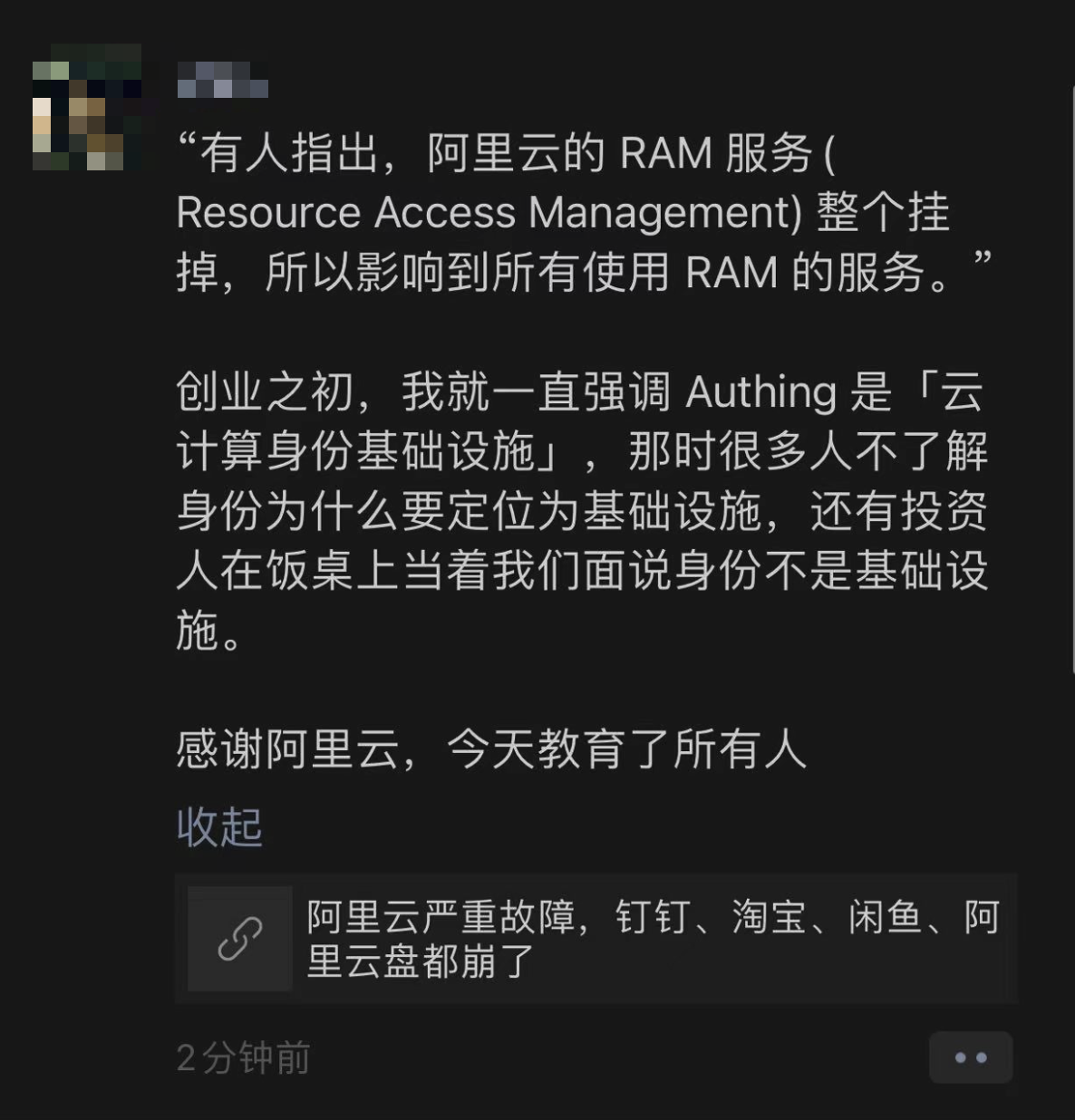
Although Alibaba-Cloud has yet to provide a post-incident analysis report, experienced engineers can determine the problem location based on the blast radius — Auth (authentication/authorization/RAM).
Hardware failures in storage/compute or data center power outages would at most affect a single availability zone (AZ), network failures would at most affect one region, but something that can cause simultaneous issues across all global regions must be a cross-regional shared cloud infrastructure component — most likely Auth, with a low probability of other global services like billing.

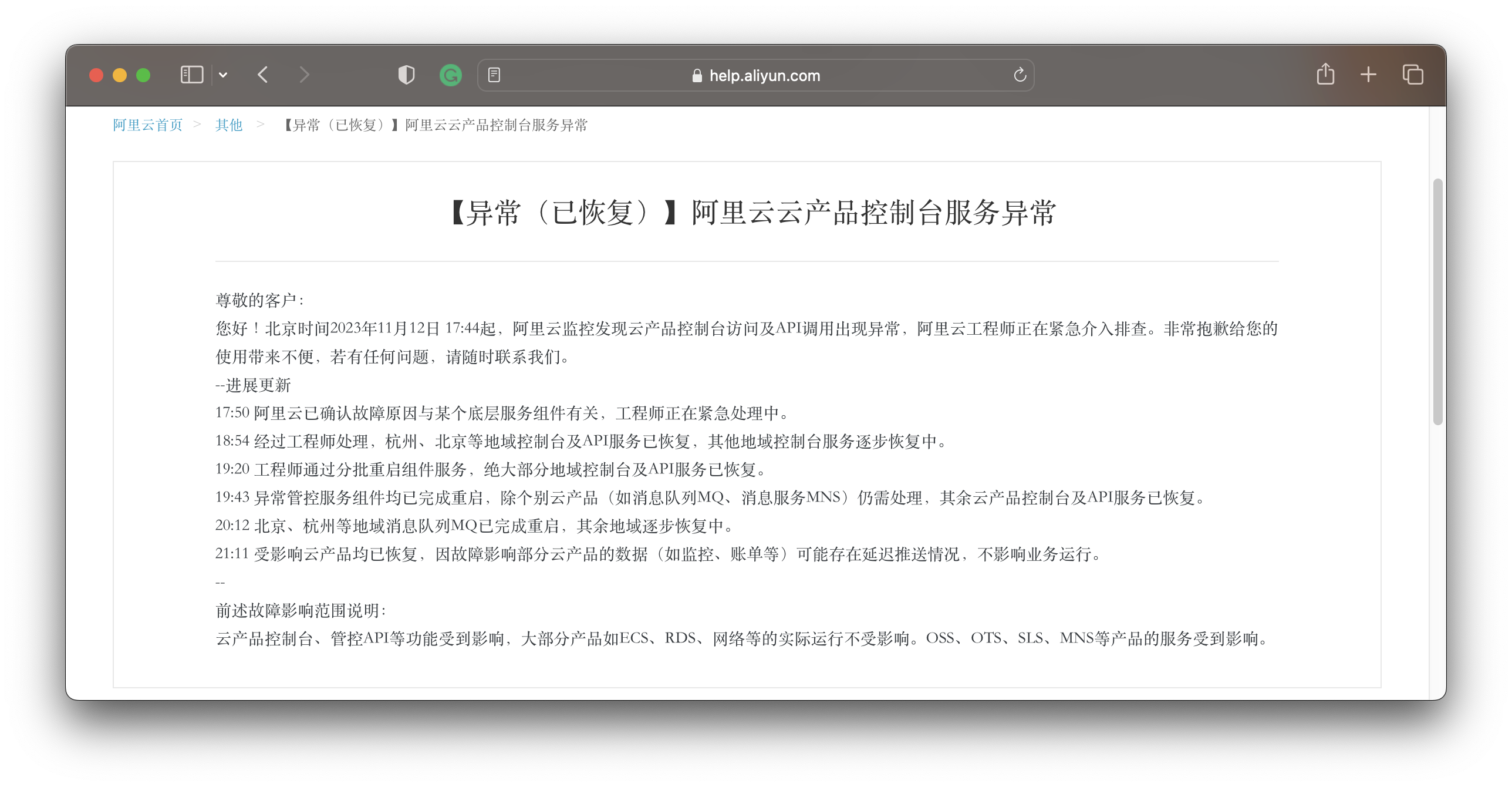
Alibaba-Cloud’s incident progress announcement: the issue was with a certain underlying service component, not network or data center hardware problems.
The root cause being Auth has the highest probability, with the most direct evidence being: cloud services deeply integrated with Auth — Object Storage OSS (S3-like), Table Store OTS (DynamoDB-like), and other services heavily dependent on Auth — directly experienced availability issues. Meanwhile, cloud resources that don’t depend on Auth for operation, like cloud servers ECS/cloud/ databases RDS and networking, could still “run normally”, users just couldn’t manage or modify them through consoles and APIs. Additionally, one way to rule out billing service issues is that during the outage, some users still successfully paid for ECS deals.
While the above analysis is just inference, it aligns with leaked internal messages: authentication failed, causing all services to malfunction. As for how the authentication service itself failed, until a post-mortem report emerges, we can only speculate: human configuration error has the highest probability — since the failure wasn’t during regular change windows and had no gradual rollout, it doesn’t seem like code/binary deployment. But the specific configuration error — certificates, blacklists/whitelists, circular dependency deadlocks, or something else — remains unknown.
Various rumors about the root cause are flying around, such as “the permission system pushed a blacklist rule, the blacklist was maintained on OSS, accessing OSS required permission system access, then the permission system needed to access OSS, creating a deadlock.” Others claim “during Double 11, technical staff worked overtime for a week straight, everyone relaxed after Double 11 ended. A newbie wrote some code and updated a component, causing this outage,” and “all Alibaba-Cloud services use the same wildcard certificate, the certificate was replaced incorrectly.”
If these causes led to Auth failure, it would truly be amateur hour. While it sounds absurd, such precedents aren’t rare. Again, these street-side rumors are for reference only; please refer to Alibaba-Cloud’s official post-mortem analysis report for specific incident causes.
What was the impact?#
Authentication/authorization is the foundation of services. When such basic components fail, the impact is global and catastrophic. This renders the entire cloud control plane unavailable, directly impacting consoles, APIs, and services deeply dependent on Auth infrastructure — like another foundational public cloud service, Object Storage OSS.
From Alibaba-Cloud’s announcement, it seems only “several services (OSS, OTS, SLS, MNS) were affected, while most products like ECS, RDS, networking etc. were not affected in actual operations”. But when a foundational service like Object Storage OSS fails, the blast radius is unimaginable — it can’t be dismissed as “individual services affected” — it’s like a car’s fuel tank catching fire while claiming the engine and wheels are still turning.
Object Storage OSS provides services through cloud vendor-wrapped HTTP APIs, so it necessarily depends heavily on authentication components: you need AK/SK/IAM signatures to use these HTTP APIs, and Auth failures render such services unavailable.
Object Storage OSS is incredibly important — arguably the “defining service” of cloud computing, perhaps the only service that reaches basic standard consensus across all clouds. Cloud vendors’ various “upper-level” services depend on OSS directly or indirectly. For example, while ECS/RDS can run, ECS snapshots and RDS backups obviously depend heavily on OSS, CDN origin-pulling depends on OSS, and various service logs are often written to OSS.
From observable phenomena, Alibaba-Cloud Drive, with core functionality deeply tied to OSS, crashed severely, while services with little OSS dependency, like Amap, weren’t significantly affected. Most related applications maintained their main functionality but lost image display and file upload/download capabilities.
Some practices mitigated OSS impact: public storage buckets without authentication — usually considered insecure — weren’t affected; CDN usage also buffered OSS issues: Taobao product images via CDN cache could still be viewed, but real-time chat images going directly through OSS failed.
Not just OSS, other services deeply integrated with Auth dependencies also faced similar issues, like OTS, SLS, MNS, etc. For example, the DynamoDB alternative Table Store OTS also experienced problems. Here’s a striking contrast: cloud database services like RDS for PostgreSQL/MySQL use the database’s own authentication mechanisms, so they weren’t affected by cloud vendor Auth service failures. However, OTS lacks its own permission system and directly uses IAM/RAM, deeply bound to cloud vendor Auth, thus suffering impact.
Technical impact is one aspect, but business impact is more critical. According to Alibaba-Cloud’s Service Level Agreement (SLA), the 3.5-hour outage brought monthly service availability down to 99.5%, falling into the middle tier of most services’ compensation standards — compensating users with 25% ~ 30% of monthly service fees in vouchers. Notably, this outage’s regional and service scope was complete!

Alibaba-Cloud OSS SLA
Of course, Alibaba-Cloud could argue that while OSS/OTS services failed, their ECS/RDS only had control plane failures without affecting running services, so SLAs weren’t impacted. But even if such compensation fully materialized, it’s minimal money, more like a gesture of appeasement: compared to users’ business losses, compensating 25% of monthly consumption in vouchers is almost insulting.
Compared to lost user trust, technical reputation, and commercial credibility, those voucher compensations are truly negligible. If handled poorly, this incident could become a pivotal landmark event for public cloud.
Comments and opinions?#
Elon Musk’s Twitter X and DHH’s 37 Signal saved millions in real money through cloud exit, creating “cost reduction and efficiency improvement” miracles, making cloud exit a trend. Cloud users hesitate over bills wondering whether to leave the cloud, while non-cloud users are conflicted. Against this backdrop, such a major failure by Alibaba-Cloud, the domestic cloud leader, deals a heavy blow to hesitant observers’ confidence. This outage will likely become a pivotal landmark event for public cloud.
Alibaba-Cloud has always prided itself on security, stability, and high availability, just last week boasting about extreme stability at their cloud conference. But countless supposed disaster recovery, high availability, multi-active, multi-center, and degradation solutions were simultaneously breached, shattering the N-nines myth. Such widespread, long-duration, broadly impactful failures set historical records in cloud computing.
This outage reveals the enormous risks of critical infrastructure: countless network services relying on public cloud lack basic autonomous control capabilities — when failures occur, they have no self-rescue ability except waiting for death. Even financial and government clouds experienced service unavailability. It also reflects the fragility of monopolized centralized infrastructure: the decentralized internet marvel now mainly runs on servers owned by a few large companies/cloud/ vendors — certain cloud vendors themselves become the biggest business single points of failure, which wasn’t the internet’s original design intent!
More severe challenges may lie ahead. Global users seeking monetary compensation is minor; what’s truly deadly is that in an era where countries emphasize data sovereignty, if global outages result from misconfigurations in Chinese control centers (i.e., you really did grab others by the throat), many overseas customers will immediately migrate to other cloud providers: this concerns compliance, not availability.
According to Heinrich’s Law, behind one serious accident lie dozens of minor incidents, hundreds of near-misses, and thousands of hidden dangers. Last December’s Alibaba-Cloud Hong Kong data center major outage already exposed many problems, yet a year later brought users an even bigger “surprise” (shock!). Such incidents are absolutely fatal to Alibaba-Cloud’s brand image and even seriously damage the entire industry’s reputation. Alibaba-Cloud should quickly provide users with explanations and accountability, publish detailed post-mortem reports, clarify subsequent improvement measures, and restore user trust.
After all, failures of this scale can’t be solved by “finding a scapegoat, sacrificing a programmer” — the CEO must personally apologize and resolve it. After Cloudflare’s control plane outage earlier this month, the CEO immediately wrote a detailed post-mortem analysis, recovering some reputation. Unfortunately, after several rounds of layoffs and three CEO changes in a year, Alibaba-Cloud probably struggles to find someone capable of taking responsibility.
What can we learn?#
The past cannot be retained, the gone cannot be pursued. Rather than mourning irretrievable losses, it’s more important to learn from them — and even better to learn from others’ losses. So, what can we learn from Alibaba-Cloud’s epic failure?
Don’t put all eggs in one basket — prepare Plan B. For example, business domain resolution must use a CNAME layer, with CNAME domains using different service providers’ DNS services. This intermediate layer is crucial for Alibaba-Cloud-type failures, providing at least the option to redirect traffic elsewhere rather than sitting helplessly waiting for death with no self-rescue capability.
Prioritize using Hangzhou and Beijing regions — Alibaba-Cloud failure recovery clearly has priorities. Hangzhou (East China 1), where Alibaba-Cloud headquarters is located, and Beijing (North China 2) recovered significantly faster than other regions. While other availability zones took three hours to recover, these two recovered in one hour. These regions could be prioritized, and while you’ll still eat the failure, you can enjoy the same Brahmin treatment as Alibaba’s own businesses.
Use cloud authentication services cautiously: Auth is the foundation of cloud services, everyone expects it to work normally — yet the more something seems impossible to fail, the more devastating the damage when it actually does. If unnecessary, don’t add entities; more dependencies mean more failure points and lower reliability: as in this outage, ECS/RDS using their own authentication mechanisms weren’t directly impacted. Heavy use of cloud vendor AK/SK/IAM not only creates vendor lock-in but also exposes you to shared infrastructure single-point risks.
Use cloud services cautiously, prioritize pure resources. In this outage, cloud services were affected while cloud resources remained available. Pure resources like ECS/ESSD, and RDS using only these two, can continue running unaffected by control plane failures. Basic cloud resources (ECS/EBS) are the greatest common denominator of all cloud vendors’ services; using only resources helps users choose optimally between different public clouds and on-premises builds. However, it’s hard to imagine not using object storage on public cloud — building object storage services with MinIO on ECS and expensive ESSD isn’t truly viable, involving core secrets of public cloud business models: cheap S3 customer acquisition, expensive EBS cash grab.
Self-hosting is the ultimate path to controlling your destiny: If users want to truly control their fate, they’ll eventually walk the self-hosting path. Internet pioneers built these services from scratch, and doing so now is only easier: IDC 2.0 solves hardware resource issues, open-source alternatives solve software issues, mass layoffs release experts solving human resource issues. Bypassing public cloud middlemen and cooperating directly with IDCs is obviously more economical. For users with any scale, money saved from cloud exit can hire several senior SREs from big tech companies with surplus. More importantly, when your own people cause problems, you can use rewards and punishments to motivate improvement, but when cloud fails, what do you get — a few cents in vouchers? — “Who are you to deserve high-P attention?”
Understand that cloud vendor SLAs are marketing tools, not performance promises
In the cloud computing world, Service Level Agreements (SLAs) were once viewed as cloud vendors’ commitments to service quality. However, when examining these agreements composed of multiple 9s, we find they can’t “backstop” as expected. Rather than compensating users, SLAs are more like “penalties” for cloud vendors when service quality falls short. Compared to experts who might lose bonuses and jobs due to failures, SLA penalties don’t hurt cloud vendors — more like token self-punishment. If penalties are meaningless, cloud vendors lack motivation to provide better service quality. So SLAs aren’t insurance policies backstopping users’ losses. In worst cases, they block substantial recourse attempts; in best cases, they’re emotional comfort placebos.
Finally, respect technology and treat engineers well
Alibaba-Cloud has been aggressively pursuing “cost reduction and efficiency improvement” these past two years: copying Musk’s Twitter mass layoffs, laying off tens of thousands while others lay off thousands. But while Twitter users grudgingly continue using despite outages, ToB businesses can’t tolerate continuous layoffs and outages. Team instability and low morale naturally affect stability.
It’s hard to say this isn’t related to corporate culture: 996 overtime culture, endless time wasted on meetings and reports. Leaders don’t understand technology, responsible for summarizing weekly reports and writing PowerPoint presentations; P9s talk, P8s lead teams, real work gets done by 5-6-7 levels with no promotion prospects but first in line for layoffs; truly capable top talent won’t tolerate such PUA frustration and leave in batches to start their own businesses — environmental salinization: academic requirements rise while talent density falls.
An example I personally witnessed: a single independent open-source contributor’s open-source RDS for PostgreSQL can outperform dozens of RDS team members’ product, while the opposing team lacks courage to defend or refute — Alibaba-Cloud certainly has capable product managers and engineers, but why can such things happen? This requires reflection.
As the domestic public cloud leader, Alibaba-Cloud should be a banner — so it can do better, not what it looks like now. As a former Alibaba employee, I hope Alibaba-Cloud learns from this outage, respects technology, works pragmatically, and treats engineers well. Don’t get lost in cash grab quick money schemes while forgetting original vision — providing affordable, high-quality public computing services, making storage and computing resources as ubiquitous as water and electricity.
References#
Should We Give Up on Cloud Computing?
Why Doesn’t Cloud Computing Make More Money Than Sand Mining?
Are Cloud Disks Just Scam Schemes?
Are Cloud Databases Just Intelligence Taxes?
Paradigm Shift: From Cloud to Local-First
Tencent Cloud CDN: From Getting Started to Giving Up
【Alibaba】Epic Cloud Computing Disaster Strikes
Grab Alibaba-Cloud’s Wool Quick, Get 5000 Yuan Cloud Servers for 300
Cloud Vendors’ View of Customers: Poor, Idle, and Starved for Love
Alibaba-Cloud’s Failures Can Happen in Other Clouds Too, and They Might Lose Data
Chinese Cloud Services Going Global? Fix the Status Page First
Can We Trust Alibaba-Cloud’s Incident Handling?
An Open Letter to Alibaba-Cloud
Platform Software Should Be as Rigorous as Mathematics — Discussion with Alibaba-Cloud RAM Team
Chinese Software Professionals Outclassed by the Pharmaceutical Industry
Why Clouds Can’t Retain Customers — Using Tencent Cloud CAM as Example
Why Does Tencent Cloud Team Use Alibaba-Cloud Service Names?
Are Customers Lousy, or Is Tencent Cloud Lousy?
Are Baidu, Tencent, and Alibaba Really High-Tech Companies?
Cloud Computing Vendors, You’ve Failed Chinese Users
Besides Discounted VMs, What Advanced Cloud Services Are Cloud Computing Users Actually Using?





